Internet crawlers, also named spiders, are bots operated by search engines, like Google, to immediately scan websites and index them. The initially stage to indexing webpages is accessing robots.txt data files by the crawlers and reading through the directions which determine which website parts are allowed or disallowed to be crawled.
Figuring out about the functionalities of robots.txt information and strategies to modify the guidelines for crawlers aids in understanding new features of site optimization and stability.
Table of Contents
What Is a Robots.txt File?
Robots.txt is a configuration file that presents recommendations for bots (primarily research motor crawlers) that consider to obtain certain pages or sections of the website. It is located in your root WordPress directory, the to start with file the crawlers see when coming into the web page.
To see this file’s directions, the lookup engine bots should support the Robots Exclusion Protocol (REP). This protocol is a conventional describing how the bots (website robots) interact with web sites. In apply, it helps make them obtain a robots.txt file and parse the details about which areas of the site they must crawl.
Nevertheless, not all internet websites have to have to have a robots.txt file because research engines usually can uncover and index all the critical website internet pages, and they will not existing unimportant internet pages in look for benefits. Possessing a robots.txt file is not a trustworthy system to retain your internet web pages off Google for two causes:
- The robots.txt file has guidance that stop bots from crawling, not indexing pages. The page can be indexed if external inbound links lead to it, even if bots don’t crawl it.
- Not all bots strictly follow the rules in the robots.txt file, even while the most essential ones, Google, Bing, and Yahoo bots, obey the REP benchmarks.
That mentioned, there are other strategies to avoid your WordPress website page from showing in research motor effects, these as introducing a noindex meta tag to a webpage or defending it with a password.
Why Robots.txt Information Are Critical for Internet site Web optimization
Simply because a robots.txt file permits you to control research robots, its guidelines appreciably affect Search engine marketing (Research Motor Optimization). The correct directives can offer your WordPress website with pretty a couple of benefits.
Properly-published recommendations can deny accessibility to poor bots mitigating their damaging impact on all round web page speed. Even so, you must bear in mind that malicious bots or e-mail scrapers may possibly dismiss your directives or even scan the robots.txt file to identify which regions of your web page to attack initially. It’s far better not to depend on the robots.txt file as your only security device and use superior security plugins if you’re experiencing difficulties with negative bots.
Even fantastic robots’ activity can overload servers or even cause them to crash. Robots.txt can have directions for a crawl delay to end crawlers from loading far too lots of parts of details at after, weighing down the servers.
Improved robots.txt directives make sure that your site’s crawl quota is utilized with highest effect and that the crawl budget for Google bots is not exceeded. Simply because there is a most range of moments bots can crawl the web page in a specified time, it is useful if they aim on genuinely relevant sections. You can obtain it by banning unimportant pages.
What You Can Do with Robots.txt
Like all other site information, the robots.txt file is saved on the world-wide-web server, and you can ordinarily perspective it by typing the site’s homepage URL followed by /robots.txt like www.anysite.com/robots.txt. The file is not connected any place on the site, so it is not likely that consumers will access it accidentally. In its place, most lookup crawlers that adhere to REP protocol will glance for this file before they crawl the web-site.
How to create and edit robots.txt
WordPress routinely generates a digital robots.txt file for your site and will save it in the root listing. By default, such a file incorporates the adhering to directives:
User-agent: *
Disallow: /wp-admin/
Make it possible for: /wp-admin/admin-ajax.php
Even so, if you’d like to modify guidance for look for robots, you need to make a true robots.txt file and overwrite the outdated file. There are two quick means to do this:
Adding policies to robots.txt
Now that you know about the gains of the robots.txt file and how you can edit it, let’s see what directives this file can have and what results it can obtain:
- user-agent: identifies the crawler (you can uncover the names of crawlers in the robots database)
- disallow: denies access to selected directories or net web pages
- permit: makes it possible for crawling of particular directories and world-wide-web pages
- sitemap: displays sitemap’s location
- crawl-delay: shows the variety of milliseconds every bot has to wait concerning requests
- *: denotes any quantity of goods
- $: denotes the conclude of the line.
The guidelines in robots.txt usually consist of two parts: the portion that specifies which robots the adhering to instruction applies to, and the instruction by itself. Glance at the case in point supplied earlier mentioned once more:
User-agent: *
Disallow: /wp-admin/
Enable: /wp-admin/admin-ajax.php
The asterisk indicator is a “wild card,” which means the guidelines apply to all bots who occur to quit by. So all bots are prevented from crawling written content in the /wp-admin/ listing. The following row overwrites the former rule letting access to the /wp-admin/admin-ajax.php file.
Best Procedures for Working with Robots.txt Files
Your company desires to draw in an audience to occur to your web-site. Use your knowledge about robots.txt and convert it into an helpful tool to enhance Search engine optimisation and encourage your products and solutions and services. Understanding about what robots.txt can and just cannot do is presently a superior start to create on your site’s rankings. Right here are some principles to recall to make certain you get the most out of robots.txt and do not hazard your site’s protection.
- Really do not use robots.txt to avert obtain to sensitive info, this kind of as private information and facts, from showing up in search engines’ final results. External resources may incorporate back links to your web page and make it indexable devoid of you recognizing it.
- The one-way links on blocked internet pages will not be indexed both, which signifies these types of one-way links will not obtain hyperlink fairness from your pages.
- It is greater to disallow directories, not web pages if you want to disguise delicate content. Bear in mind that some malware bots could glance for sensitive internet pages to target on in the robots.txt file.
- You can use the disallow command to keep crawlers off the copy pages, for example, equivalent content in diverse languages. On the other hand, the buyers will not see them in lookup engines, which will not support your site rank.
- Use appropriate syntax when modifying the robots.txt file – even the slightest error can make the complete web page unindexable.
- After you generate and add the robots.txt file, assure your coding is right by navigating to Google Tests Device and subsequent the instructions.
- It is commonly a great follow to include the spot of a sitemap at the finish of robots.txt instructions to guarantee the crawl bots really do not skip anything essential. The sitemap URL may perhaps be located on a various server than the robots.txt file, and you can incorporate additional than one sitemap.
How Do Well-liked WordPress Web sites Use Their Robots.txt Information?
Let’s see how popular internet sites created with WordPress manage their robots.txt information.
observer.com

The Observer makes use of the default WordPress robots.txt instructions disallowing all bots from crawling /wp-admin/ directory besides for the /wp-admin/admin-ajax.php file and which include areas of their sitemap data files.
rollingstone.com
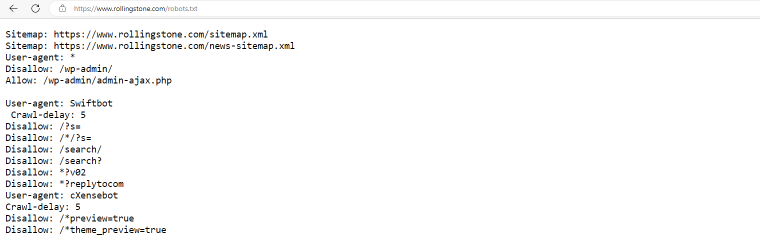
The Rolling Stone web site has a robots.txt file that consists of sitemaps, default limitations for all bots to crawl /wp-admin/ documents, and particular guidance for Swiftbots and cXensebots not to crawl specific internet pages and have a five-millisecond delay among requests.
vogue.com
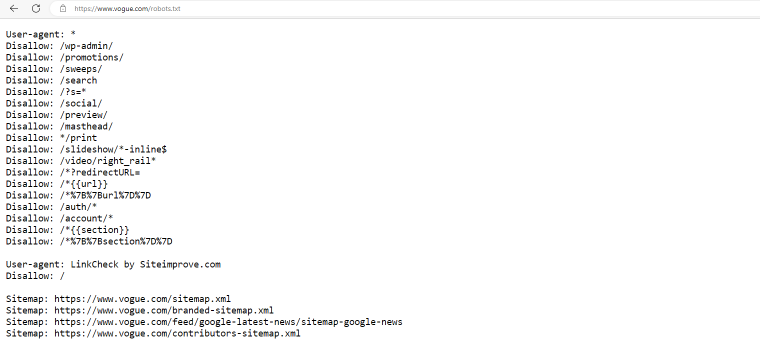
Vogue.com denies obtain to a greater listing of pages to all bots and restricts accessibility to the whole website to Linkcheck bots.
katyperry.com

Here’s an instance of how an Search engine marketing plugin modifies a robots.txt file. In this situation, it is the function of the Yoast plugin, and all bots are authorized to crawl the full web site. The lines setting up with a ‘#’ indication are not directives but comments.
crocoblock.com
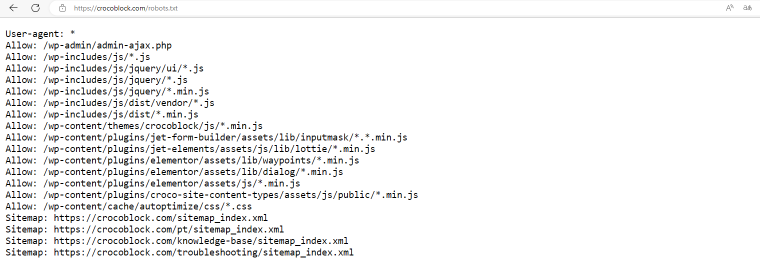
The robots.txt file for the Crocoblock web-site places no limits on world-wide-web crawlers. In its place, we indicated the information we desired the bots to concentrate on.
Summary
The WordPress robots.txt file is situated in the root directory of every single website, and it is the 1st location website crawlers stop by to uncover directions about which pieces of the web-site should or shouldn’t be assessed, indexed, and ranked. Remaining capable to create and edit your personal robots.txt file may enable improve your internet site for Seo and maintain the fantastic bots under management.
If you want to keep away from safety risks, adhere to the very best methods when editing robots.txt information, and discover what this device can and cannot be made use of for.